Valence Swarming & Perspective Maps
Originally published at nodescription.substack.com
A proposed tool for multiplayer cognition
Note: this was written from my raw notes (and the app’s context of prior discussions) within ChatGPT. You can read the raw chat log here, but I feel this is the more palatable format. And thanks to Defender and Michael Garfield for the direct and indirect inspiration for these thought-paths. Prototypes coming soon! :)
I’ve been thinking a lot lately about what it would mean to move beyond broadcast — not just to make media more interactive in the superficial sense, but to create something closer to continuous shared sensing between a speaker and the people listening.
What follows is an early grounding of an idea I’ve been circling: a lightweight, no-look interface that lets audiences stream their felt responses in real time, and a mapping layer that helps both sides make sense of the resulting swarm.
This is not a finished proposal. It’s a sketch of a direction that feels worth exploring.
The core intuition
Imagine an audience of thousands watching a live talk or video.
Instead of occasional polls, emoji bursts, or chat messages, each person has a simple touch surface under their thumb. As they listen, they can subtly express their moment-to-moment valence — some blend of:
- leaning toward
- neutral / disengaged
- leaning away
The key is continuity and low friction. Ideally, the interface becomes almost invisible — something you can operate without looking, while remaining fully immersed in the content.
If enough people participate, the system begins to function less like “feedback” and more like a collective sensory organ.
What changes when feedback becomes continuous?
Traditional broadcast is structurally one-way. Even when interactive elements are added, they tend to be:
- episodic
- coarse
- lagged
- and heavily mediated
But if you can capture thousands of tiny signals per second, you get something qualitatively different.
You can begin to ask:
- Where is the audience collectively leaning right now?
- Where are they splitting?
- Who is drifting away versus leaning in?
- How do people’s trajectories evolve over the course of a talk?
At that point, the audience is no longer a black box. It becomes a dynamic landscape that both the speaker and the audience themselves can explore.
The rough workflow
At a high level:
-
Mobile mode — participants provide continuous thumb input while watching a talk (live or remote).
-
Valence capture — the system records moment-to-moment “toward / neutral / away” signals.
-
Swarm synchronization — many participants stream data aligned to the same timecode.
-
Time slicing — the stream is segmented where meaningful divergence appears.
-
Perspective mapping — dimensional reduction reveals clusters and trajectories of audience experience.
-
Interpretation loop — insights can flow back into the broadcast itself.
That last step is the interesting one. If done carefully, the speaker is no longer guessing about the room — they are in dialogue with a living mirror.
Why continuous input instead of buttons?
A reasonable concern (raised by George Charnley in conversation) is adoption friction: will people really want to hold their thumb down during an event?
I suspect this depends heavily on audience and context. But more importantly, the design goal here is to get as close as possible to low-cognitive-load sensing.
There’s a meaningful difference between:
- noticing a feeling
- deciding to act
- finding a button
- pressing it
…and simply letting your thumb drift slightly in response to what you’re already feeling.
The latter can begin to approach something like a physiological signal — not EEG, of course, but closer in spirit than discrete reactions. With enough use, the touch may become almost background, like wearing a shirt. The brain tends to tune out stable interfaces.
That said: this is an empirical question. Small-scale experiments will tell us more than speculation.
The real design dials
If the basic premise holds, the interesting work is in the tuning. Several open questions feel especially important.
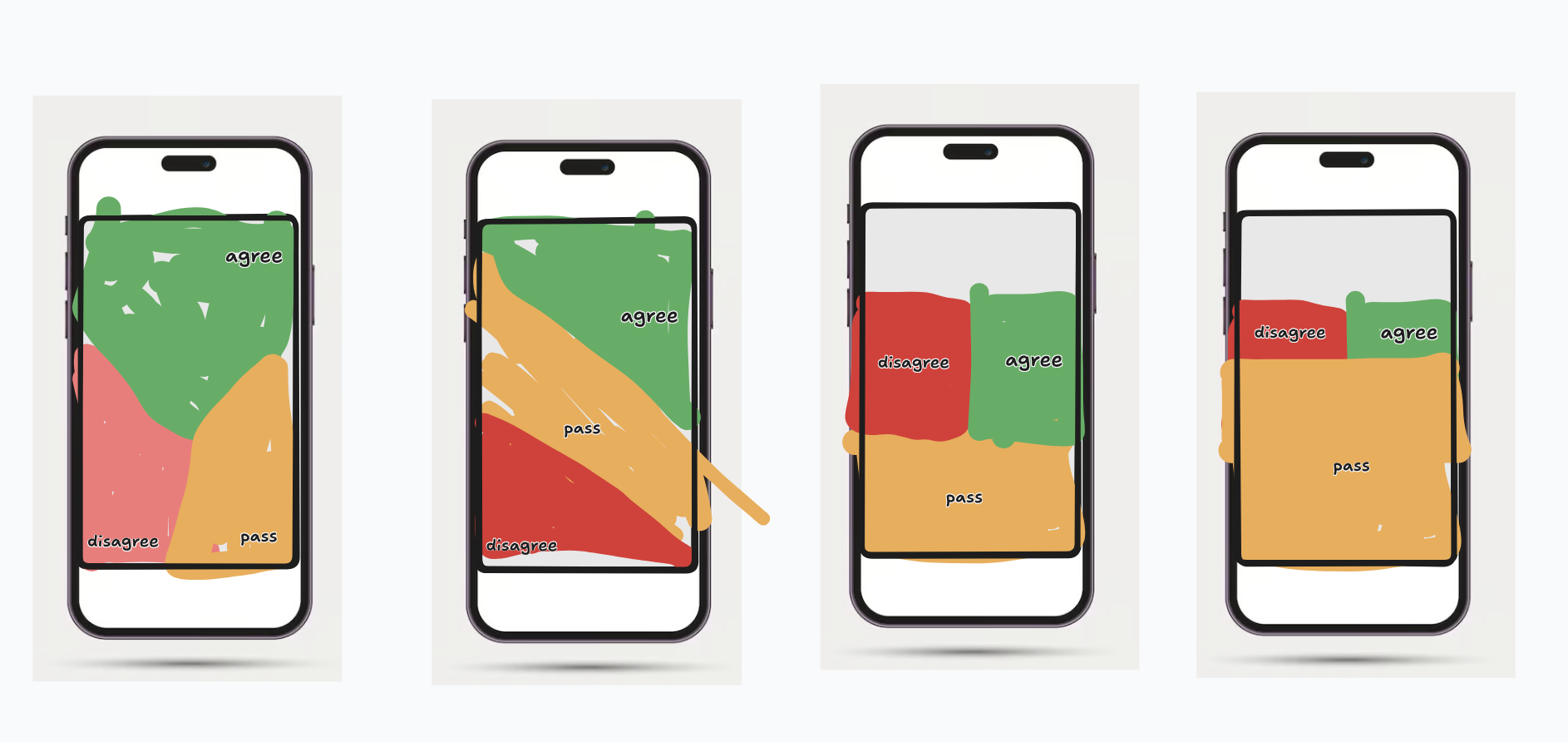
1. What are the three states?
There is probably no universally correct labeling. Options include:
- toward / neutral / away
- agree / pass / disagree
- attracted / neutral / repelled
- open / steady / closed
Each framing subtly primes behavior. My current hunch is that the negative / away signal is the hardest for people to give, which means the interface may need to actively legitimize and normalize its use.
This is fertile ground for A/B testing.

2. What geometry yields the cleanest signal?
Possible layouts include:
- linear slider
- tripolar triangle
- corner hotspots
- radial zones
Different geometries will produce different noise characteristics and user behaviors. We shouldn’t assume the most intuitive UI is the most information-rich. It’s all about what helps the most insightful, high-resolution signal to appear in the dimensionally reduced space of the perspective map.
3. What baseline behaviour do we encourage?
Two contrasting modes:
Agreeable default Positive sociable, affirming “agreement” feedback as default.
Spike train model Baseline neutrality, with targeted activation/inhibition when attention or arousal rises.
The second may produce sharper signal, and perhaps mirror the spike train model of biological neural networks in interesting ways.
4. What system constraints shape engagement?
Small environmental tweaks could matter a lot:
- video speed
- pause permissions
- whether feedback unlocks features
- whether the interface is visible or no-look
- whether participation is individual or social
These are not just UX choices — they shape the cognitive mode people enter while watching.
Not just where people are — but the paths between
I’ve been borrowing the phrase “trajectory analysis” from single-cell omics, but it needs a bit of translation to land properly in this context.
In biology, trajectory methods aren’t primarily about watching one specific cell change over time. They’re about reconstructing the latent developmental pathways that cells tend to follow — the structured routes through state space that many cells independently travel.

That’s the closer analogy here.
The goal is not mainly to watch whether this particular viewer changed their mind during a talk (though sometimes that may be visible). The deeper aim is to surface the shared pathways of belief and felt response that exist across the audience as a whole.
In other words:
less “who changed” more “what are the roads that change tends to follow?”
Mapping the paths of possible movement
When you take thousands of time-aligned valence streams and map participants by the pattern of their reactions, something interesting can emerge.
You don’t just get clusters.
You often get structure between clusters — elongated shapes, bridges, gradients, forks.
These are the beginnings of what I’m calling paths in value space.
They suggest:
- common routes along which people tend to resonate
- regions where perspectives are relatively stable
- and boundary zones where divergence reliably appears
At a high level, this becomes a kind of cartography of possible selves-in-relation.
Not who any one person must become.
But the shape of the landscape we seem to move through together.
The 10,000-foot view
What becomes visible at sufficient scale is not primarily individual opinion change, but something more structural:
- the attractors
- the ridgelines
- the basins
- the narrow passes where audiences tend to split
From this altitude, the map starts to answer a different class of questions:
- Where are the natural fault lines in how this material is received?
- Which experiential positions are adjacent versus far apart?
- Where do people reliably travel if they move at all?
- Which regions appear isolated or rarely visited?
This is why the continuous signal matters. Episodic polling tends to flatten these pathways into discrete bins. Dense time-series data preserves the geometry.
Why this grounding matters
If we frame this system only as “real-time audience feedback,” it sounds like a faster applause meter.
If we frame it as “mind-change detection,” it invites overclaim and skepticism.
But if what we’re actually building toward is:
a coarse but scalable map of the latent topology of audience sense-making
…then the ambition and the limits both become clearer.
This is exploratory instrumentation.
Early cartography.
A way of asking, at scale:
What are the shapes of movement available to us, together, in response to meaning?
What this is not
It’s not:
- a replacement for deliberation
- a measure of truth
- a perfect read of internal state
- or a guaranteed path to better discourse
It’s an instrument. Like any instrument, it can clarify or distort depending on how it’s used.
The real question is whether it can help us move from broadcast monologue toward something more like collective sensemaking in motion.
Where this might start
My current instinct is to begin small:
- tens to hundreds of participants
- recorded content (for controlled experiments)
- rapid iteration on the input model
- heavy attention to signal quality
If the signal proves meaningful at small scale, larger deployments become more interesting.
If not, we learn quickly and adjust.
An open question
The thing I keep wondering is less technical and more phenomenological:
What does it feel like when a speaker and an audience are in a tight, continuous feedback loop — but one that preserves reflection rather than collapsing into noise?
We have many systems for speaking. We have fewer for truly listening at scale.
This feels like one small probe into that space.
If you’re experimenting with adjacent ideas — or if you have strong skepticism — I’d be very interested to compare notes.